
xPath это такой язык запросов, который позволяет среди множества элементов веб-страницы найти нужный, — и обратиться к нему, чтобы достать необходимые данные:
- Заголовок и описание.
- Названия статей с количеством просмотров.
- Список ссылок.
- Цены на товары.
- Изображения и т. п.
xPath поддерживают платные инструменты для парсинга (например, Screaming Frog Seo Spider), его выражения можно использовать в программировании на JavaScript, PHP и Python, и даже сделать простой бесплатный парсер прямо в Google Таблицах. Разбираемся, как именно — на трех практических примерах.
Когда начинаешь изучать большинство видео/статей по теме, начинает взрываться мозг — кажется, что все это очень сложно и подвластно только крутым технарям/хакерам. На самом деле все 200 встроенных функций xPath (как сообщает туториал W3C) знать совсем не обязательно, и на практике освоить язык получается гораздо проще. Процесс напоминает привычное ориентирование в папках и файлах в компьютере, а сами выражения xPath — адреса вроде «C:\Program Files (x86)\R-Studio».
1. Сбор и проверка заголовков и метатегов
Работа с заголовками (h1) и метатегами (title и description, реже keywords) — одна из составляющих поисковой оптимизации сайта. SEO-специалист (маркетолог, предприниматель) может проверять эти текстовые фрагменты на наличие, по длине, вхождениям определенных запросов. Если нужна массовая проверка, лучше воспользоваться специальным парсером (например, от Promopult или Click.ru), но небольшую задачу можно легко решить прямо в Google Spreadsheets.
Подготовка таблицы и разбор синтаксиса IMPORTXML
Начать можно с дизайна самой таблицы. Допустим, в первой колонке (A) будут ссылки на страницы, а правее уже результаты, извлеченные данные: H1, тайтл, дескрипшн, ключевые слова.
Тогда стоит первую строку отдать под заголовки (если планируются десятки ссылок, не помешает «Вид → Закрепить → 1 строку»), в A2 указать URL (можно пока любой — для проверки работоспособности) и приступить к написанию первой функции. (А так как текстовые фрагменты довольно длинные, можно заодно выделить все ячейки, нажать «Формат → Перенос текста → Переносить по словам».)
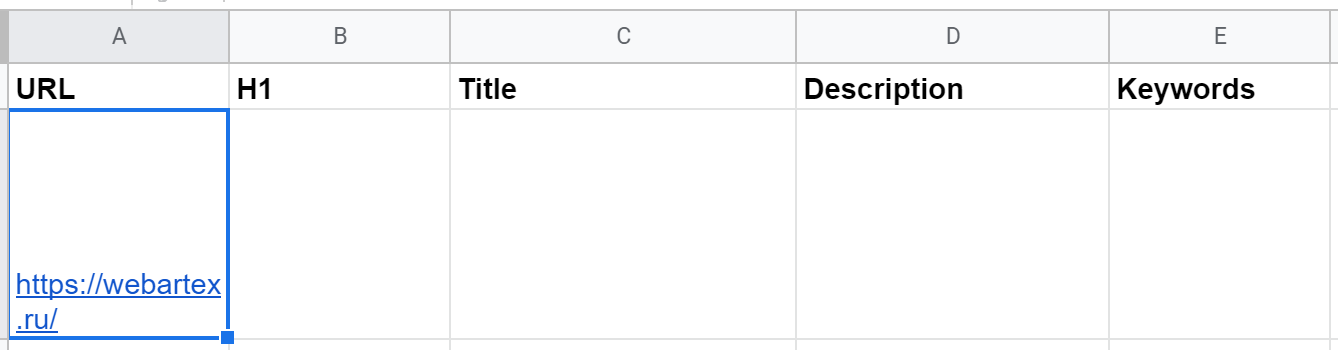
Для импорта данных с сайтов (в форматах HTML, XML, CSV) в Google Таблицах есть функция IMPORTXML. Она принимает такие аргументы:
- Полный адрес веб-страницы с указанием протокола (например, "https://"). Можно передать сам URL в кавычках или адрес ячейки, где он лежит.
- Непосредственно запрос xPath — тоже в кавычках, так как это тоже текстовая строка.
- locale — локальный код для указания языка и региона, необязательный параметр, по умолчанию используются настройки самого документа.
Читайте также: 20+ продвинутых функций Google Таблиц (Spreadsheets)
Составление функций для импорта XML с разными запросами xPath
Для парсинга H1 получится довольно просто: =IMPORTXML(A2;"//h1").
"//" это оператор для выбора так называемого корневого узла — откуда нужно будет сразу взять данные или же «плясать» дальше (к дочернему элементу, соседнему или др.). В данном случае не нужно прописывать длинный путь, указывать дополнительные параметры — тег <h1> такой один единственный (как правило, но может быть и несколько заголовков первого уровня, тогда запрос "//h1" выгрузит их в несколько строк).
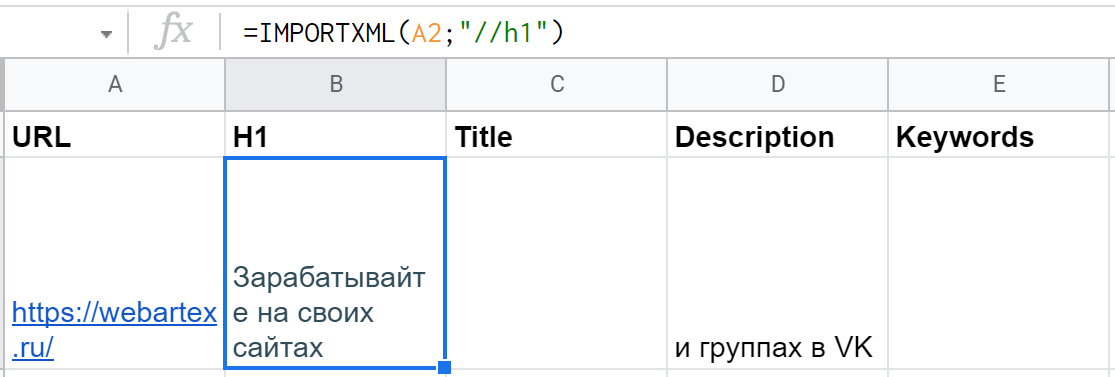
Правда, есть нюанс — часть заголовка первого уровня оказывается в ячейке D2, а там нужны совсем другие данные. Все из-за тега <br>, который внутри <h1> используется для перевода строки. Решение — функция самого xPath "normalize-space()", в которую нужно упаковать текст из H1. Дополненная функция получается такой: =IMPORTXML(A2;"normalize-space(//h1)")
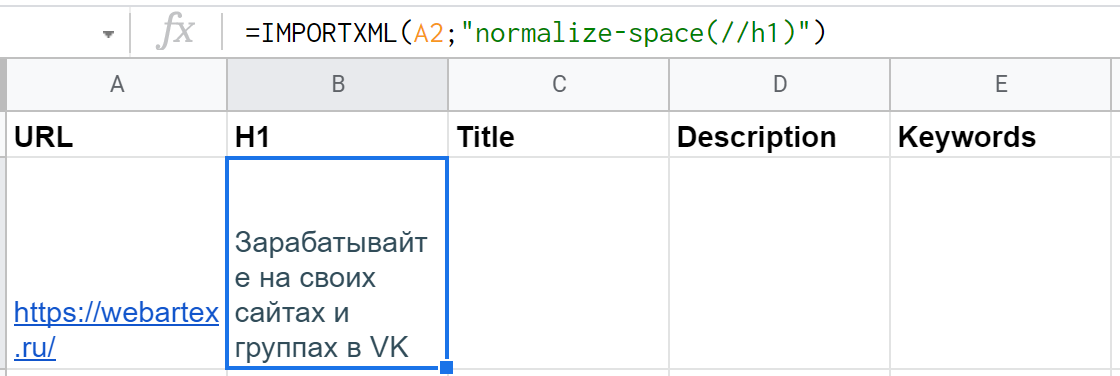
В ячейке C2 — по тому же принципу, только выражение xPath, соответственно, будет "//title".
А вот для загрузки дескрипшна в соседнюю ячейку D2 нельзя указать просто "//description", потому что такого отдельного тега нет. Эти данные лежат в теге <meta>, у которого есть дополнительный параметр (атрибут) — "name" со значением "description".
Если в запросе xPath нужно указать не просто элементы веб-страницы, а элементы с конкретным атрибутом, то соответствующие условия указываются в квадратных скобках. Название атрибута пишется с собакой "@", а его значение передается через одинарные кавычки. Если нужно проверить эквивалентность, то условие записывается просто как «атрибут = значение».
То есть для решения этой задачи нужно указать элемент так: "//meta[@name='description']".
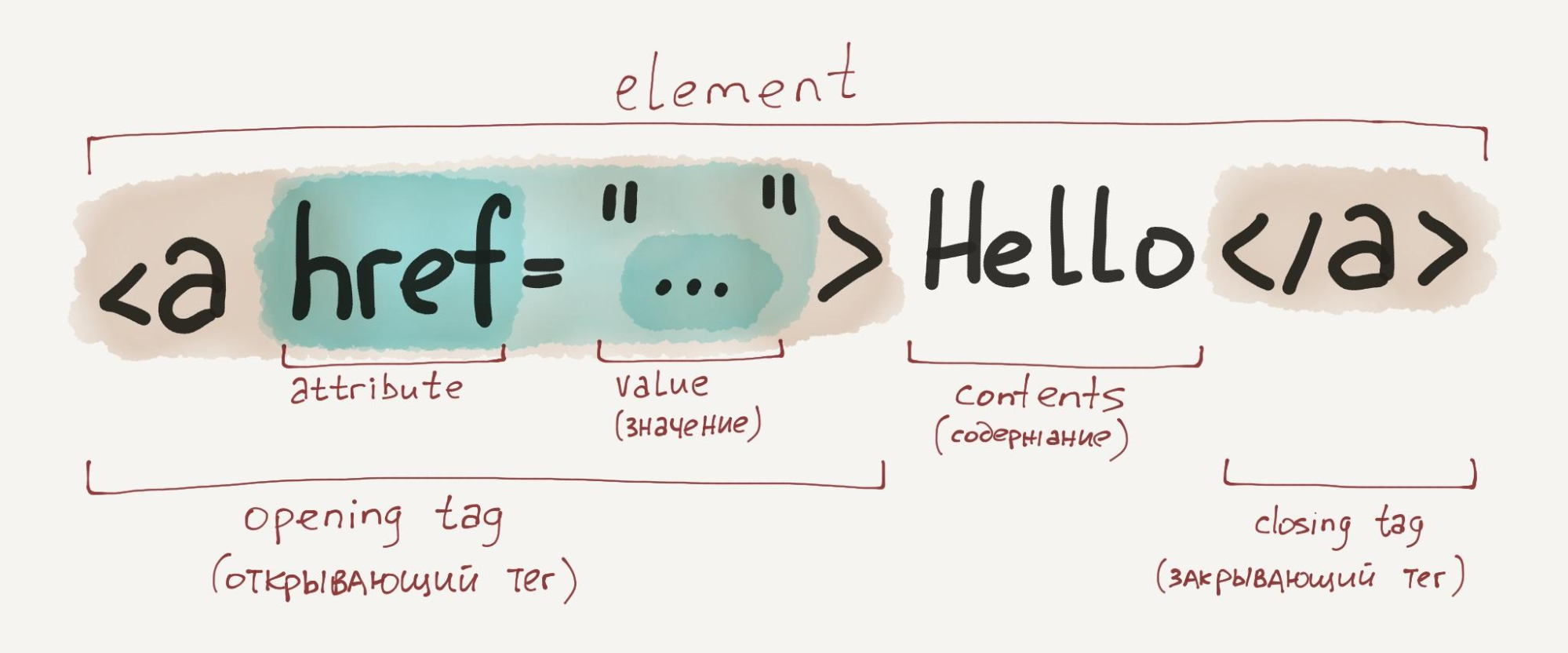
Однако если оставить такое выражение, то функция IMPORTXML вернет значение #N/A — значит, нет данных для импорта. Хотя путь к элементу указан верно. Дело в том, что внутри этого тега <meta> нет ничего — результат соответствующий.
Это хорошо видно, если открыть исходный код страницы (например, через сочетание клавиш Ctrl + U в Google Chrome). У <meta> нет закрывающего тега </meta>, как это бывает у многих других, получается, нет и внутреннего содержания. Нужные данные лежат в другом атрибуте — @content.
Решение — дополнить запрос xPath, через "/" указав путь к конкретному атрибуту выбранного элемента. В данном случае вся формула будет такой: =IMPORTXML(A2;"//meta[@name='description']/@content")
Если нужно указать не корневой элемент (узел), а его параметр или вложенный тег, тогда уже используется одинарный слеш, а не двойной. По аналогии с URL страниц сайтов или адресами файлов и папок операционной системы.
По такому же принципу составляется запрос для метатега с ключевыми словами — "//meta[@name='keywords']/@content". Если все ок, то, значит, можно протягивать формулы ниже, а в столбец URL добавлять новые адреса.

Если нужно, аналогичным образом можно извлекать и другие данные: подзаголовки H2—H6, метатеги для разметки OpenGraph и Viewport, robots и др.
Читайте также: Микроразметка на сайте: что это, для чего нужно и как внедрить
Бонус: оценка полученных метатегов и заголовков
Допустим, нужно проверить, находится ли длина title и description в пределах нормы. Для этого можно воспользоваться функцией гугл-таблиц ДЛСТР (LEN). Она работает довольно просто: на входе текстовая строка, на выходе — число символов.
Согласно рекомендациям из блога Promopult, отображаемая длина тайтла в Google — до 50-55, а в Яндексе — до 45-55. Поэтому желательно не писать его слишком длинным, по крайней мере в первых 45–55 символах должна быть законченная мысль, самое главное о странице.
Чтобы не создавать дополнительных ячеек с цифрами по количеству символов, можно прописать формулу LEN в условном форматировании. Выделить третий столбец C, кликнуть в меню на «Формат → Условное форматирование», выбрать в списке «Правила форматирования» вариант «Ваша формула». И туда уже прописать, допустим, =LEN($C$2:$C)>55. А цвет, например, желтый, который как бы будет сигнализировать: «Тут надо посмотреть!».
В данном примере строка C2 пожелтеет, так как длина title составляет 59 знаков, а не 55. Но в принципе вся ключевая мысль, призыв к действию, умещается в лимит, так что все нормально.

По такому же алгоритму можно сделать оценку description. В вышеупомянутой статье blog.promopult.ru сказано: лучше, чтобы вся важная информация метаописания умещалась в 100-120 символов.
А еще там есть рекомендация не указывать в метатеге keywords больше 10 ключевых слов. Но чтобы проверить это, нужен не подсчет длины, а количества самих слов, разделенных запятыми.
В гугл-таблицах нет специальной функции, которая считает количество вхождений определенных символов в текстовую строку, но эту задачу можно решить через условное форматирование с помощью такой формулы: =COUNTA(SPLIT($E$2:$E;","))>10. Небольшой ликбез:
- SPLIT — разделяет текст по определенным символам и выводит в разные ячейки. Два обязательных параметра: 1) собственно, текст, который нужно разделить, или ссылку на ячейку с таковым 2) один или несколько символов в кавычках, по которым как раз и нужно разделять текст.
- СЧЁТЗ (COUNTA) подсчитывает количество значений в наборе данных: принимает неограниченное число аргументов (значений и диапазонов). В данном случае забирает на вход результаты SPLIT, выдающей массив текстовых значений, и подсчитывает их общее число.

Получилось, что количество keywords на странице webartex.ru составляет 14, а не 10 штук, значит, их лучше подсократить. Яндекс может использовать этот метатег при ранжировании страницы, но большое количество ключевых слов может, наоборот, привести к пессимизации, исключению из индекса.
«Поисковое продвижение» — бесплатный видеокурс по SEO в обучающем центре CyberMarketing. В программе структура поисковой выдачи, санкции поисковых систем, инструменты для сбора семантического ядра и другие важные темы. Преподаватель — Евгений Костин, руководитель департамента продаж системы Promopult.
2. Парсинг ссылок из топ-10 поисковика
Допустим, нужно регулярно мониторить топ Яндекса по определенному запросу, чтобы узнать, попал ли туда конкретный сайт и на какую позицию. Можно с помощью xPath извлечь все ссылки с органической выдачи, а благодаря текстовым функциям Google Таблиц уже искать совпадения с названием нужного сайта.
Поиск и анализ нужных элементов через DevTools
В качестве примера — запрос «отложенный постинг». Для начала нужно в браузере Chrome перейти на соответствующую страницу, кликнуть правой кнопкой на один из элементов, который нужно будет извлечь (пусть это будет ссылка ниже заголовка), и нажать на «Просмотреть код» (горячие клавиши — Ctrl + Shift +I). Тогда откроются «Инструменты разработчика» (Chrome DevTools) с кодом этого элемента.
В коде документа сразу можно заметить древовидную структуру. На самом верху — корневой тег <html>, внутри на одном уровне <head> и <body>, затем <body> раскрывается на десятки <div> и <script>, а в некоторых <div> еще другие <div> с <ul>, <li>, <h2> и т. п. Написание xPath-запроса напоминает квест: нужно правильно описать искомый элемент и путь к нему.

Напоминаем: страница состоит из элементов, а каждый элемент включает тег и содержание (что между открывающим и закрывающим тегом), а еще в открывающем теге может быть дополнительная информация: атрибуты и их значения. В данном случае необходимые данные — ссылка на страницу, которая попала в топ Яндекса — находятся в значении атрибута "href" тега <a>, у которого еще есть атрибут "class" со значением "Link Link_theme_outer Path-Item link path__item i-bem link_js_inited"
(А этот тег <a> находится внутри тега <div> с атрибутом "class" и значением "Path Organic-Path path organic__path"… но весь путь писать нет смысла, если сам <a> достаточно уникальный и правильно находится.)
Фрагмент кода (на скриншоте он не помещается целиком):
<div class="Path Organic-Path path organic__path"><a class="Link Link_theme_outer Path-Item link path__item i-bem link_js_inited" tabindex="0" data-counter="["b"]" data-log-node="ip71w0i-02" href="https://blog.cybermarketing.ru/7-servisov-otlozhennogo-postinga-v-socialnye-seti-i-messendzhery/" target="_blank"><b>blog.cybermarketing.ru</b><span class="Path-Separator" aria-hidden="true" aria-label=" ">›</span>7-servisov…postinga-v…seti…</a></div>
Но прежде чем писать запрос xPath, стоит проверить — действительно ли все нужные элементы имеют соответствующие атрибуты и значения. "href", понятно, будет везде разный, а вот что насчет "class" со значением "Link Link_theme_outer Path-Item link path__item i-bem link_js_inited"?
Для этого в окне «Инструменты разработчика» нужно нажать «Ctrl + F» и внизу появится поле «Find by string, selector, or xPath». Если вставить эту большую и страшную строку, видно, что подсвечивается с десяток элементов.
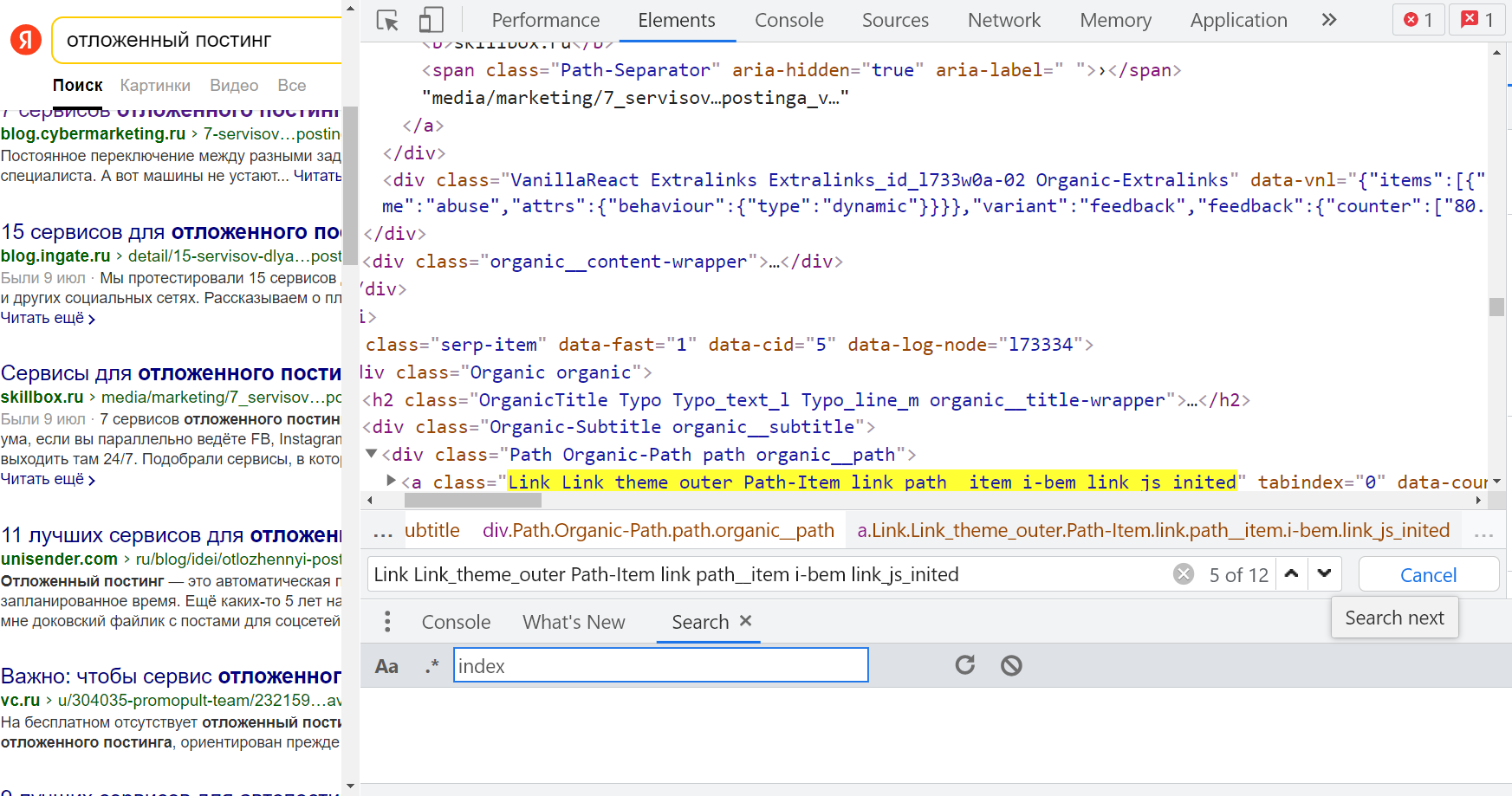
Ссылка из блока быстрых ответов не попадает — отлично, иначе она бы дублировалась. Но есть нюанс — и органическая, и платная выдача имеет такое же значение атрибута "class" тега <a>. Но их можно развести через дополнительное условие (все рекламные ссылки начинаются с "http://yabs.yandex.ru/").
Читайте также: Чем отличается контекстная реклама от таргетированной
Написание xPath-локатора с учетом изученных элементов и их параметров
Вспоминаем: "//" — это оператор, который выбирает так называемый корневой узел — элемент для непосредственного извлечения данных или тот, от которого нужно будет дальше «плясать». Значит, нужно начать с «//a». Но если оставить так, то загрузятся все <a> со страницы, а для решения задачи нужны конкретные. То есть нужно указать, что нужен элемент <a> с атрибутом @class, у которого есть конкретное значение.
Делаем, как это уже было с метатегом дескрипшн из предыдущего раздела: атрибут с собакой, значение в одинарных кавычках, все условие в квадратных скобках → //a[@class='Link Link_theme_outer Path-Item link path__item i-bem link_js_inited'] Можно проверить работоспособность запроса сразу же в «Инструментах разработчика» — в поле «Find by string, selector, or xPath». Вроде все работает.
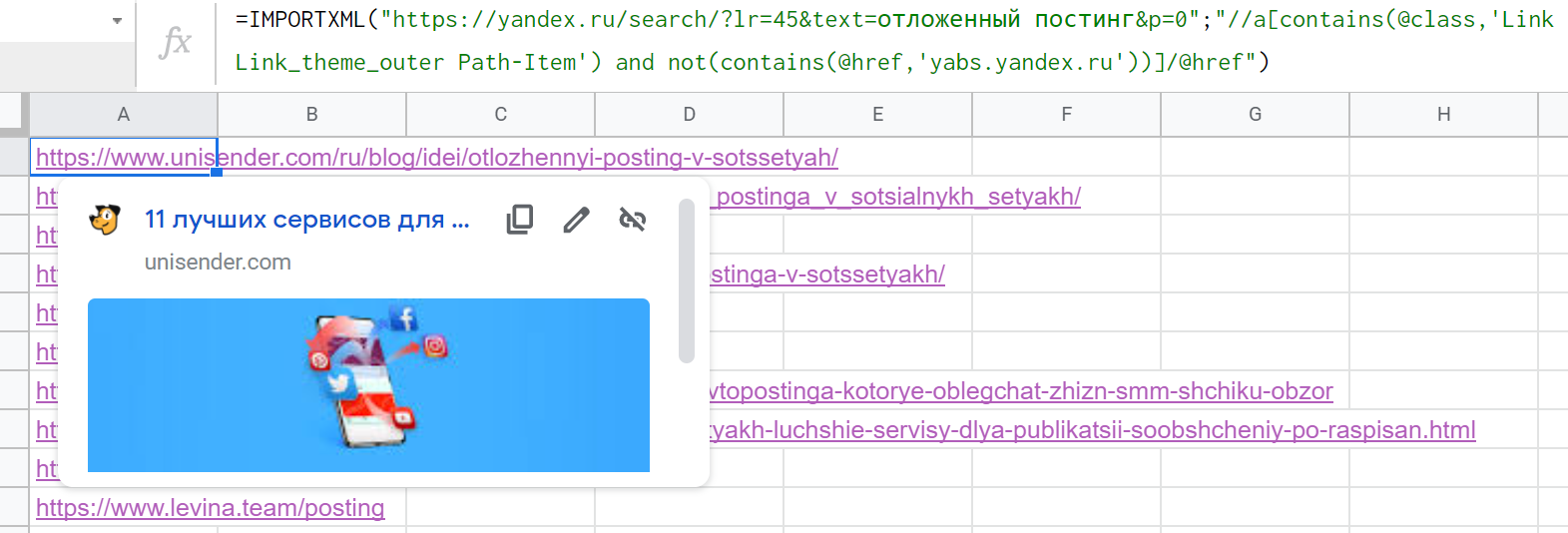
Если перенести в Google Таблицы, формула получится такой: =IMPORTXML("https://yandex.ru/search/?lr=45&text=отложенный постинг&p=0";"//a[@class='Link Link_theme_outer Path-Item link path__item i-bem link_js_inited']") Но результат — #N/A!, нет данных для импорта.
Ах, да — как и в случае с description и keywords, искомые данные лежат в другом атрибуте. То есть нужно продолжить путь с помощью "/@href". Но функция снова не может импортировать данные.

На самом деле в атрибуте это не один такой класс с длинным названием, а несколько, которые разделены пробелами. Возможно, поэтому IMPORTXML не может найти данные по условию [@class=']. Решение — искать не полное совпадение, а часть значения атрибута с помощью функции contains.
Если взять начало "Link Link_theme_outer Path-Item", то поиск по документу в DevTools выдает те же элементы, ничего лишнего не подмешивается. Значит, можно написать запрос таким образом: "//a[contains(@class,'Link Link_theme_outer Path-Item')]"

Функция contains через запятую принимает два аргумента: название параметра, где нужно искать вхождение, и текстовую строку, которую нужно искать. В данном случае нужно указать @class, но можно любой другой атрибут (или text(), если требуется найти вхождения во внутреннее содержание элемента). Альтернативой может стать другая функция starts-with — она ищет не в любом месте, а в начале строки. В данном случае результат такой же при "//a[starts-with(@class,'Link Link_theme_outer Path-Item')]/@href".
Осталось только исключить из списка ссылки из контекстной рекламы, ведь нужна только органическая выдача. Для этого требуется указать два условия: чтобы взять все @href в теге <a> с классом, содержащим "Link Link_theme_outer Path-Item", но в то же время, чтобы в этих @href не было ссылок, где URL включает "yabs.yandex.ru". Решение — дополнить запрос xPath таким образом: "//a[contains(@class,'Link Link_theme_outer Path-Item') and not(contains(@href,'yabs.yandex.ru'))]/@href"
Что здесь нового: логический оператор "and" указывает, что должны быть выполнены оба условия, а функция not() выполняет другую логическую операцию — отрицание. contains() внутри нее возвращает TRUE, когда находит в ссылке "yabs.yandex.ru", но в списке таковые как раз не нужны, поэтому TRUE надо превратить в FALSE. А логическое «И» работает только, когда оба условия — TRUE. Поэтому на выходе желаемый результат.
Кстати, вместо <a> с классом, включающим "Link Link_theme_outer Path-Item", можно взять другую ссылку — с заголовков страниц. То есть составить запрос так: "//a[contains(@class, 'OrganicTitle-Link') and not (contains(@href, 'yabs.yandex.ru'))]/@href" (ну и, конечно, вместо второй функции contains можно взять start-with, в данном случае все рекламные ссылки будут начинаться одинаково, с "http://yabs.yandex.ru").
А если захочется парсить не первую страницу, а, допустим, вторую, то достаточно в URL — первом аргументе функции IMPORTXML — увеличить значение параметра &p (в конце ссылки) с нуля до единицы. То есть изменить адрес на "https://yandex.ru/search/?lr=45&text=отложенный постинг&p=1".
Читайте также: Исчерпывающий гид по поисковым операторам Google и Яндекса
3. Выгрузка статистики по популярным статьям в блоге
Допустим, автору (редактору, маркетологу или блогеру) хочется следить за популярными материалами в других медиа, чтобы черпать идеи по новым темам уже для своего ресурса. Можно делать это вручную — заходить на каждый сайт, скроллить, тратить время на поиск соответствующего блока — или собирать такие данные в таблицу. Рассмотрим, как это можно делать, на примере сайта Yagla (не самый посещаемый тематический ресурс, но интересный вариант с точки зрения освоения языка xPath).
Изучение сайта и подходящих элементов
На сайте yagla.ru много разных блоков, но для этих целей больше подходят два: «Обсуждаемое» (в самом верху) и «Самые читаемые статьи за последние 3 недели» чуть пониже. Информации по просмотрам нет, но есть количество комментариев (чтобы узнать просмотры, нужно открывать конкретную страницу, но, если нужно, можно с помощью дополнительных IMPORTXML загружать данные и по каждой из них).
Для начала: кликнуть правой кнопкой мыши на один из нужных заголовков в вышеперечисленных блоках, выбрать «Просмотреть код». Chrome DevTools подсвечивают тег <p> с атрибутом @class равным "small-post__title". Но если ввести это значение в поле «Find by string, selector, or xPath» видно, что оно есть и у материалов другого блока «Примеры роста конверсий, заказов и прибыли», который не нужно импортировать.
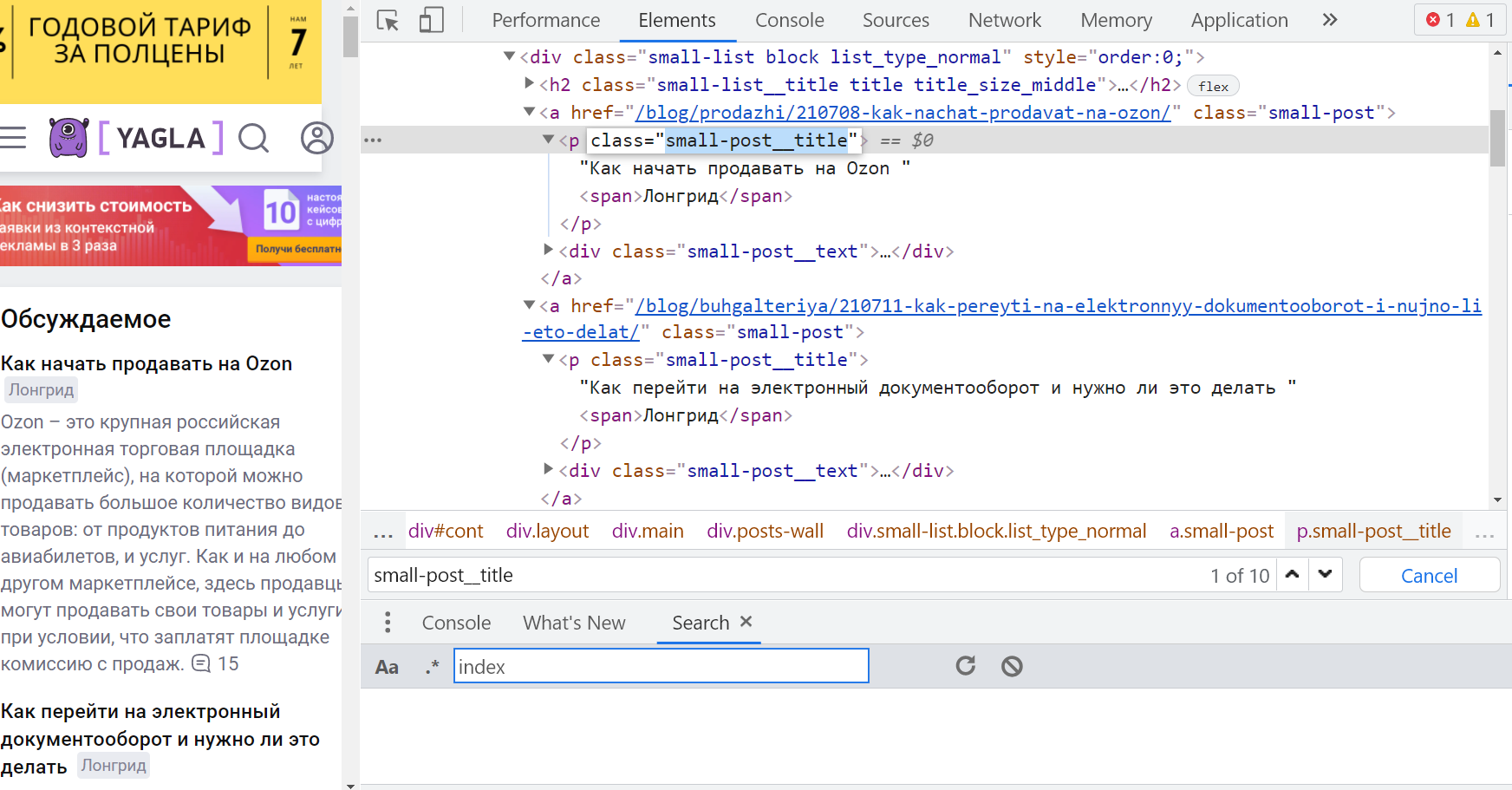
Родительский элемент, в который вложен вышеупомянутый <p>, — это <a> с классом 'small-post'. Но он еще более неуникальный, на странице таких 40 штук. Соседний (на одном и том же уровне) с <a> элемент — <h2> с классом "small-list__title title title_size_middle" тоже найден на странице в количестве четырех штук.
Но ведь можно прописать путь к элементу не только по значению атрибута, но и его содержанию, тексту.
Читайте также: Чек-лист: как проверить верстку
Составление запроса xPath
Обратиться к элементу можно и так — "//*[text()='Обсуждаемое ']", чтобы взять только тот, где текст полностью соответствует строке 'Обсуждаемое'. Сам тег в таком случае тоже прописывать необязательно.
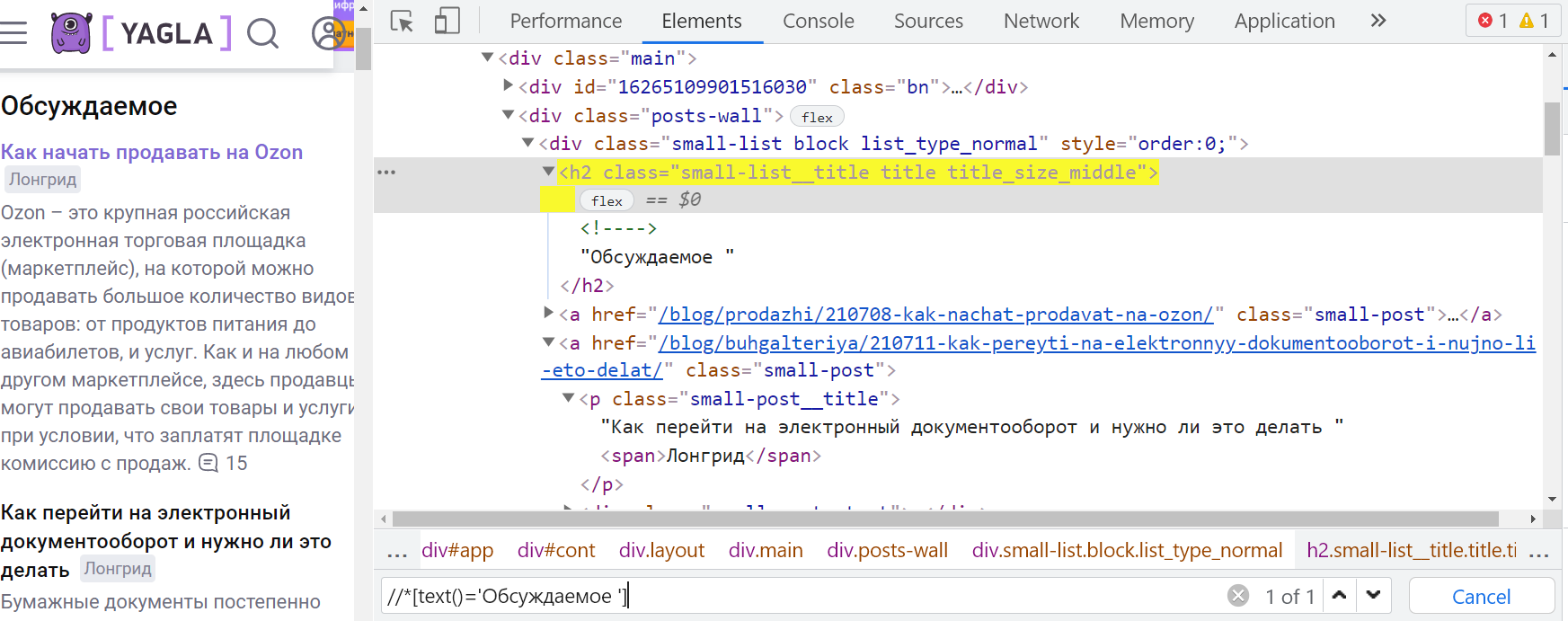
Но при написании дальнейшего пути не получится как обычно продолжить с одинарным слешем, ведь нужен не потомок этого элемента, а элемент того же уровня — «сосед» («брат», «сестра»). В таких случаях нужен специальный оператор — 'following-sibling::'. В итоге выражение xPath получится таким: "//*[text()='Обсуждаемое ']/following-sibling::a/p". (Дополнительно указывать классы для <a> и <p> нет необходимости, так как других похожих вариантов путей нет.)
Таким же способом можно составить выражение для загрузки данных из другого блока: "//*[text()='Самые читаемые статьи за последние 3 недели ']/following-sibling::a/p"
Базовая настройка и оформление таблицы
Как вариант. В ячейку A1 положить заголовок «Обсуждаемое», а ниже — в A2 — уже написать функцию: =IMPORTXML("https://yagla.ru/";"//*[text()='Обсуждаемое ']/following-sibling::a/p"). Затем оставить необходимое пространство (если ячейки будут заняты, функция не сможет отобразить результаты), A5 отдать под следующий заголовок, а в A6 — вторую формулу: =IMPORTXML("https://yagla.ru/";"//*[text()='Самые читаемые статьи за последние 3 недели ']/following-sibling::a/p")
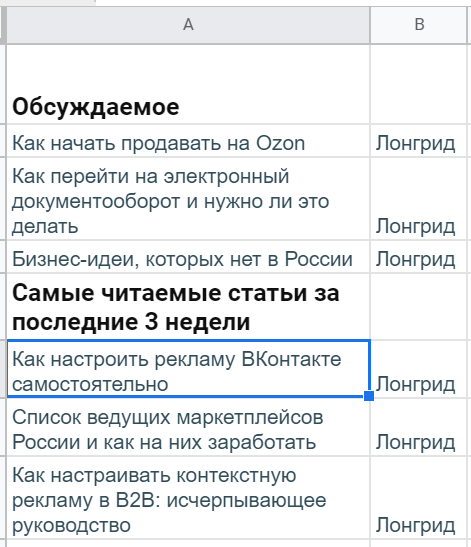
Внутри искомого <p> есть еще <span> с указанием формата, поэтому IMPORTXML требуется дополнительный столбец справа. (Так как эта информация излишняя, можно просто выделить все ячейки B, кликнуть правой кнопкой и выбрать «Скрыть столбец».)
'following-sibling::' — это одна из осей, основы запросов языка xPath. Есть и другие, например, 'child::' — возвращает множество потомков на один уровень ниже; 'attribute::' — выдает, соответственно, атрибуты; 'parent::' — ищет родительский узел. И с частью этих осей мы уже знакомы, просто для наиболее распространенных действуют сокращения. Так, child:: вообще прописывать необязательно, а attrubute:: заменяется на '@'.
Бонус: прокачка мини-парсера в Google Spreadsheets
Допустим, названия статей мало, нужны еще и просмотры, которых нет на главной странице. Тогда придется немного усовершенствовать гугл-таблицу. Разберем на примере блока «Обсуждаемое» — с другим все будет так же.
Для начала нужно выгрузить URL’s материалов. Как обычно ссылки лежат в атрибутах @href тега <a>, так что достаточно просто поменять концовку выражения xPath: "//*[text()='Обсуждаемое ']/following-sibling::a/@href".
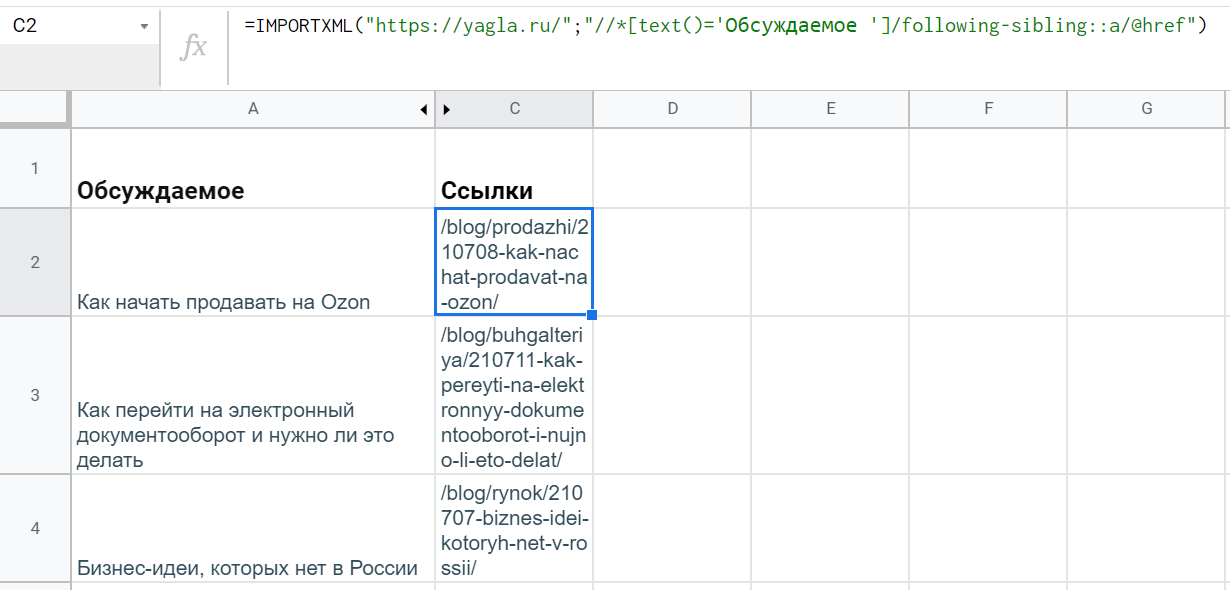
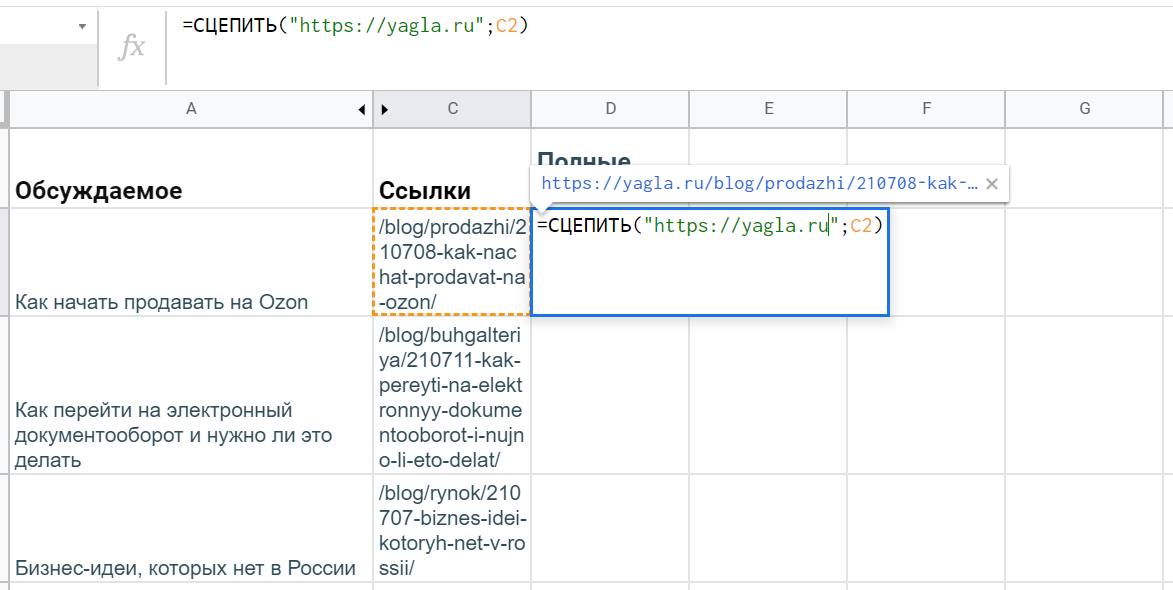
Правда, ссылки не полные, а относительные — нужно превратить их в URL’s с названием домена. Решить задачу можно с помощью текстовой функции гугл-таблиц — СЦЕПИТЬ (CONCATENATE). Она работает просто: принимает на вход несколько строк, а возвращает объединенный текст.
Дальше уже к каждой странице сделать отдельные запросы xPath, чтобы извлечь данные со счетчика просмотров. Если посмотреть через DevTools, таковые находятся в теге <div> c атрибутом @class равным 'post__prop'. Однако элемент есть и наверху, и внизу, а в таблице нужен один. В такой ситуации в квадратных скобках указывается индекс, порядковый номер (если говорить терминами xPath — предикат).
Судя по шпаргалкам и справочникам, кажется, что нужно просто написать "//div[@class='post__prop'][1]", но в таблице все равно оказываются два значения — да еще и с лишними пустыми ячейками.
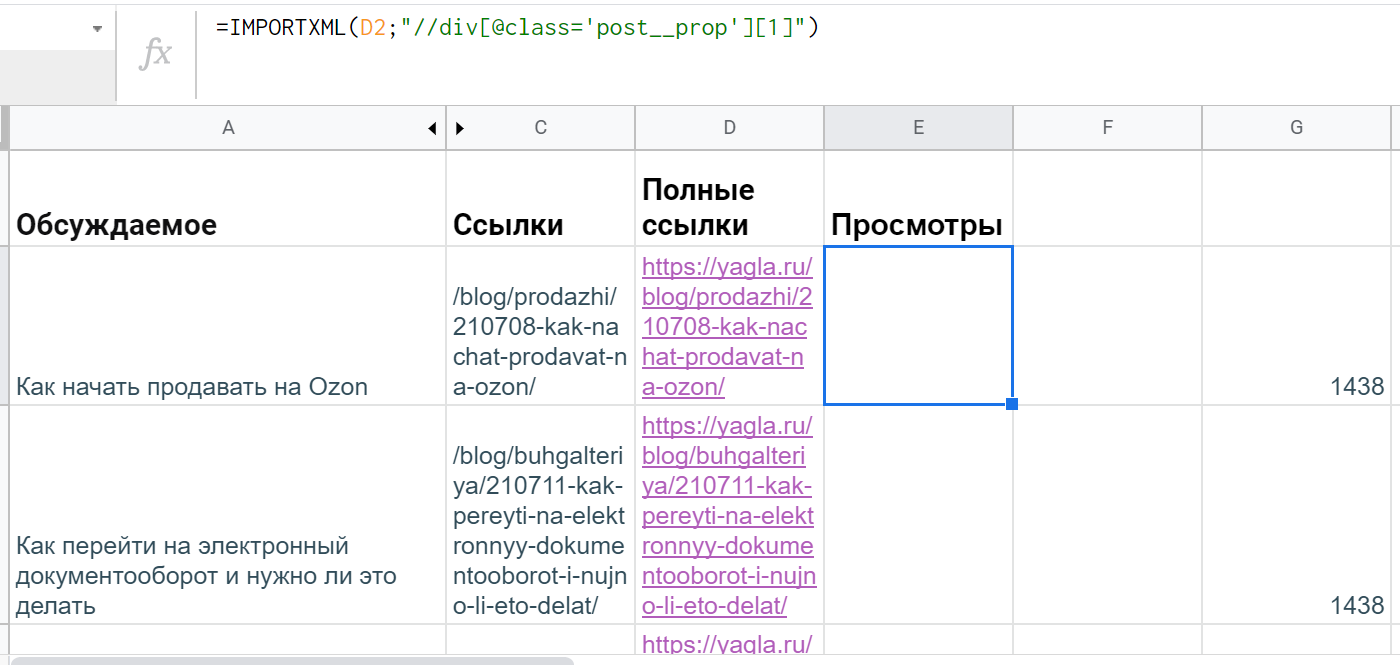
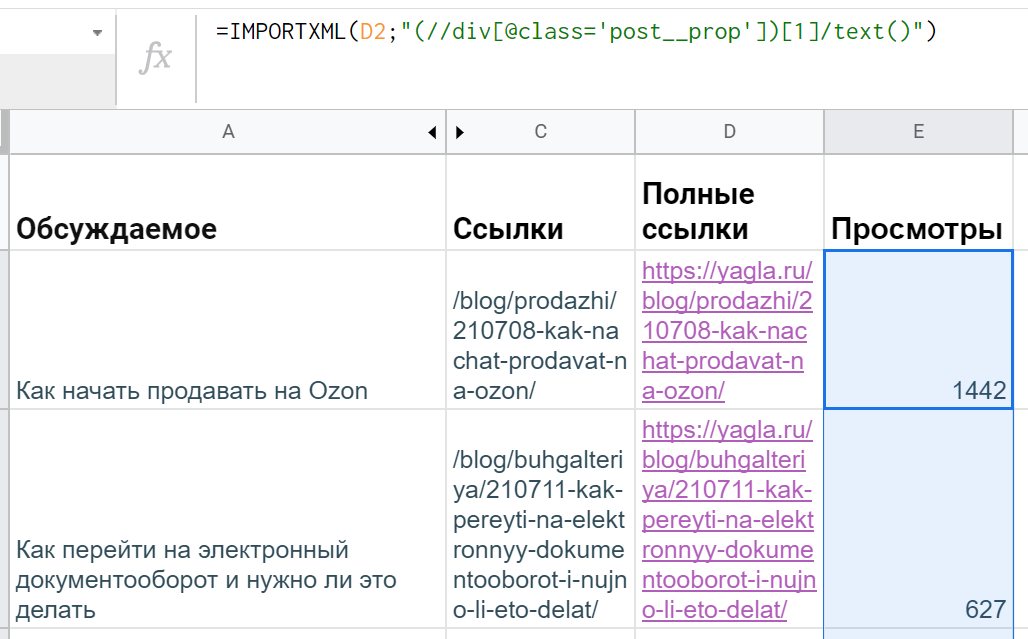
Однако эксперты Stackoverflow разъясняют, что такой синтаксис работает только для последовательности узлов, а если нужен корневой элемент, то понадобятся дополнительные скобки: "(//div[@class='post__prop'])[1]".
А лишние ячейки появляются из-за того, что внутри этого div есть еще теги. Чтобы почистить данные, понадобится применить функцию text(). Итоговая формула в гугл-таблицах получается такой: =IMPORTXML(D2;"(//div[@class='post__prop'])[1]/text()")
Остается только протянуть ее ниже — для всех строк с выгруженными URL статей.
Читайте также: Где вести блог, если нет своего сайта: 10 платформ для личного и корпоративного блогинга
Подытожим
xPath в гугл-таблицах — мощная штука, однако подходит только для решения относительно простых задач.
Так, при наличии большого количества формул типа IMPORTHTML, IMPORTDATA, IMPORTFEED и IMPORTXML результаты могут грузиться очень долго — а польза парсинга как раз в том, что можно быстро добывать свежие данные. К тому же, например, статистику Яндекс.Вордстат не получится извлечь через xPath — для работы нужна авторизация, да и даже при ручном сборе сервис может замучать капчей.
Поэтому для более серьезных задач по продвижению/оптимизации нужны профессиональные инструменты, например, Promopult. Там большой выбор решений для SEO- и PPC-специалистов: парсинг Wordstat и метатегов, сбор поисковых подсказок и кластеризация запросов, поиск и генерация объявлений и др. Один запрос стоит от 0.01 руб.
