
Google Таблицы (Google Spreadsheets) — табличный, а не текстовый редактор, тем не менее там часто приходится иметь дело именно с текстом. Рассказываем о соответствующих функциях.
ДЛСТР (LEN)
ДЛСТР (LEN) — функция для вычисления длины строки. Пригодится, если работаете в Google Sheets с контент-планами, текстами объявлений, метатегами — сразу можно проверить, соответствует текст нужным критериям или нет.
Синтаксис простой, аргумент один — текстовая строка (можно указать прямо в формуле или взять из ячейки). Например, =ДЛСТР("Блог CyberMarketing про интернет-маркетинг") вернет значение 42. Учитываются все символы, включая пробелы и переводы строки.
Если нужно проверить тайтлы страниц, а сами они пока неизвестны, можно вложить в LEN функцию IMPORTXML: =ДЛСТР(IMPORTXML(B2;"//title")) В данном случае результатом станет длина метатега TITLE, полученного для URL, который лежит в ячейке B2.
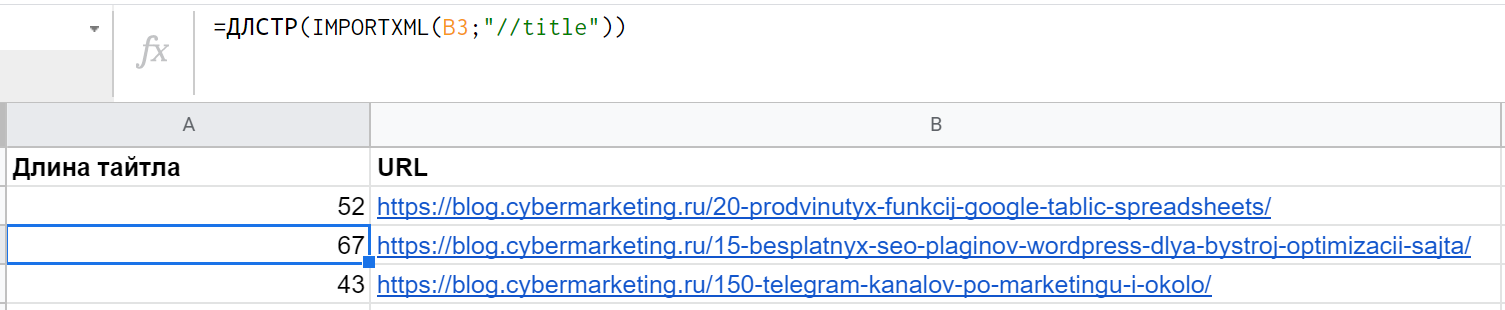
Но вообще решать такие задачи с помощью парсера Click.ru гораздо проще и удобнее.
СТРОЧН (LOWER), ПРОПИСН (UPPER)
СТРОЧН (LOWER) приводит все символы к нижнему регистру, а ПРОПИСН (UPPER) — наоборот, к верхнему. Обе текстовые функции принимают один аргумент — строку в кавычках или ячейку с текстом. Получается, конструкция =ПРОПИСН(СТРОЧН("CYBERMARKETING")) выведет ту же самую строку — "CYBERMARKETING".
Но на практике часто можно обойтись без этих функций. Для поиска без учета регистра есть ПОИСК (SEARCH) — о ней чуть позже. А, например, у QUERY, которую мы разбирали в предыдущей статье, есть свои встроенные функции — upper() и lower() — для приведения строк к единому регистру.
СЦЕПИТЬ (CONCATENATE), JOIN, TEXTJOIN
Все три функции объединяют несколько строк в одну. Работают похожим способом, но есть некоторые отличия.
CONCATENATE (СЦЕПИТЬ) дословно сцепляют несколько строк между собой по очереди. Синтаксис: =СЦЕПИТЬ("Hello";", ";"World";"!")
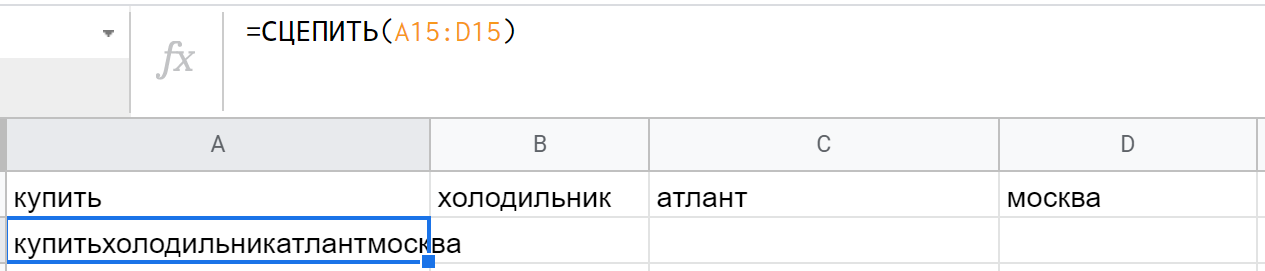
Чтобы они не слипались между собой, придется каждый раз добавлять между ними пробел (или другой символ). Например: =СЦЕПИТЬ(A15;" ";B15;" ";C15;" ";D15) Или создавать таблицу, где в одном столбце — нужные слова, в другом — соединители. (Если в параметре указан диапазон — минимум по 2 ячейки в высоту и ширину — функция будет объединять значения по строкам.)
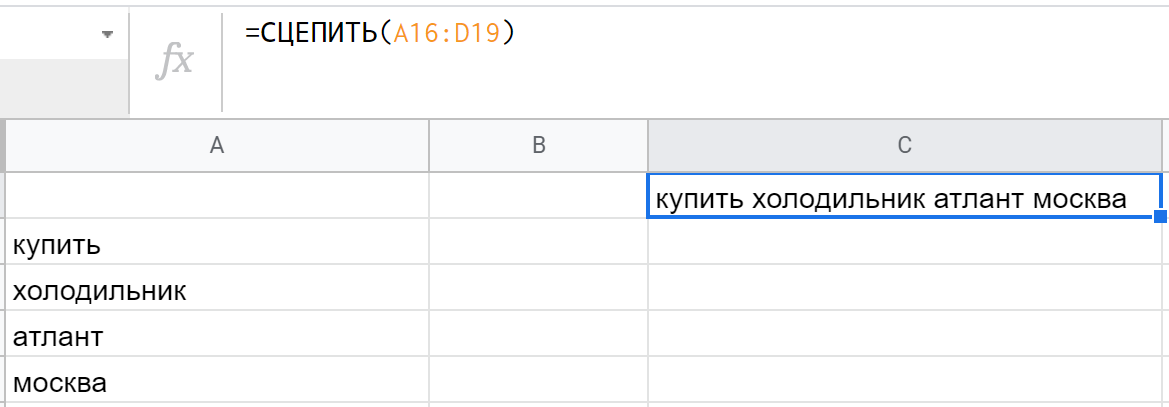
Как вы понимаете, СЦЕПИТЬ далеко не самая удобная функция. JOIN же позволяет сразу задать единый разделитель для всех строк в массиве/диапазоне: =JOIN(" ";A16:A19) даст такой же результат, как на предыдущем скриншоте — при этом не надо беспокоиться за возможный лишний символ в конце строки.
В JOIN можно спокойно объединять сразу несколько массивов данных, например: =JOIN("&";{"https://site.ru/?";"utm_source=yandex"};{"utm_medium=cpc";"utm_campaign=campaign"}) А если не указать разделитель, то все будет работать так же, как и у CONCATENATE.
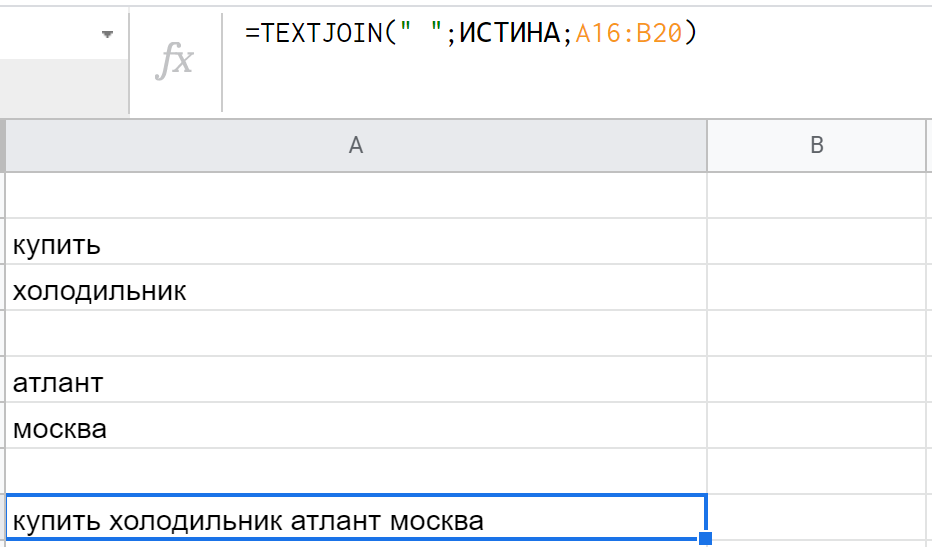
Следующая функция подойдет лучше, если в массиве/диапазоне встречаются пустые строки — ведь в JOIN они создают лишние пробелы. А TEXTJOIN делает все то же самое, только есть дополнительный аргумент, который указывает: включать пустые строки или нет. Синтаксис: =TEXTJOIN(" ";ИСТИНА;A16:B20), где первый параметр передает пробел в качестве разделителя, второй говорит, что нужно игнорировать пустые строки, а третий — дает диапазон значений для соединения.
Кстати, помимо функций, можно использовать такой оператор как ‘&’. К примеру, ="Cyber"&"Marketing" спокойно сработает и выдаст "CyberMarketing". Очень удобная фишка при создании всяких динамических таблиц (дашбордов/конструкторов), где нужно кастомизировать запрос для QUERY.
А подробнее о том, что делать с ключевыми словами, вы сможете узнать с помощью статей, вебинаров, курсов по SEO от CyberMarketing.
СЖПРОБЕЛЫ (TRIM)
Если проблема с пробелами все же есть, ее поможет решить специальная функция — СЖПРОБЕЛЫ (TRIM). Она чистит их в начале и конце текста, а также убирает повторяющиеся символы, например, двойные пробелы.
Синтаксис простой и понятный, аргумент один — строка целиком или ссылка на ячейку: =СЖПРОБЕЛЫ(" Hello, World! ")
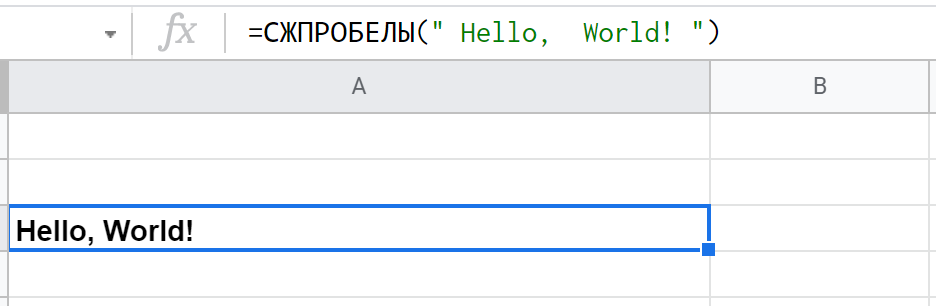
Незаменимая штука при работе с большими таблицами, где сотни ключевых фраз, метатегов или других необработанных данных, собранных из разных источников.
ЛЕВСИМВ (LEFT), ПРАВСИМВ (RIGHT), ПСТР (MID)
Все три функции извлекают из строки один или несколько символов: первая берет их слева, вторая — справа, третья — прямо из середины. Примеры:
- =ЛЕВСИМВ("Привет, мир!";6) — тут получится просто "Привет".
- =ПРАВСИМВ("Привет, мир!"; 4) — здесь от строки останется только "мир!".
- =ПСТР("Привет, мир!"; 4; 3) — выведет лишь "вет".
С ЛЕВСИМВ и ПРАВСИМВ все должно быть и так понятно (кстати, последним параметром может быть ноль, тогда функция просто вернет пустую строку). А вот ПСТР работает так: вторым аргументом принимает номер символа, с которого нужно начать извлечение подстроки, а третьим — длину извлекаемой подстроки. (Важно: отсчет начинается с 1, а не с нуля.)
Конечно, в работе редко бывает заранее известно, где в какой строке и на сколько символов надо отступить. Как правило, такие функции используют в сочетании с другими, например, ДЛСТР и ПОИСК/НАЙТИ.
Читайте также: Почему в тексте не нужны ключевые слова в точном (прямом) вхождении
SPLIT
SPLIT разделяет текст — по одному или нескольким символам-разделителям — и выводит полученные фрагменты в разные ячейки. Сами символы при этом не возвращает. Простой пример: =SPLIT(A10;"/")
Все аргументы:
1. Текст, который нужно разделить на части. Строкой или ссылкой на ячейку.
2. Символ(-ы) для разделения — тоже строкой, в кавычках.
3. Тип разделителя (необязательно). По умолчанию ИСТИНА — функция разделяет текст по каждому символу, который указан во втором параметре. Если поставить ЛОЖЬ, то разделение будет происходить только по всей последовательности символов.

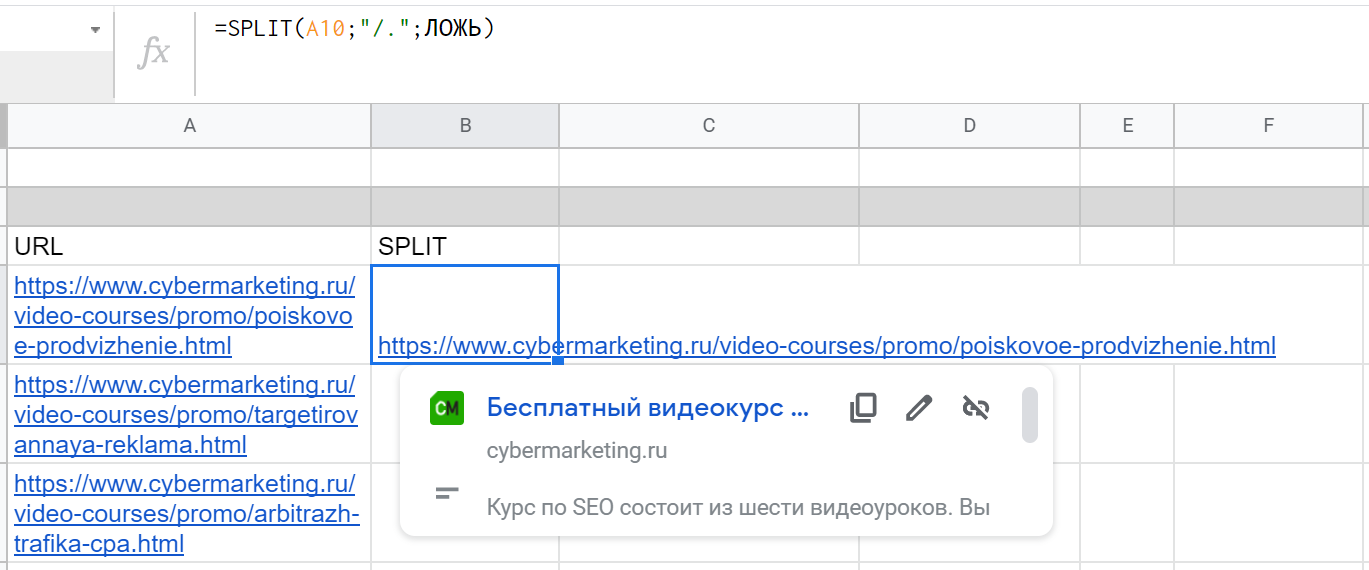
4. Тоже необязательный параметр, который определяет, нужно ли удалять пустые ячейки после разделения. По умолчанию ИСТИНА — два последовательных разделителя будут считаться одним. Если ЛОЖЬ, то между этими разделителями будет создана пустая ячейка.
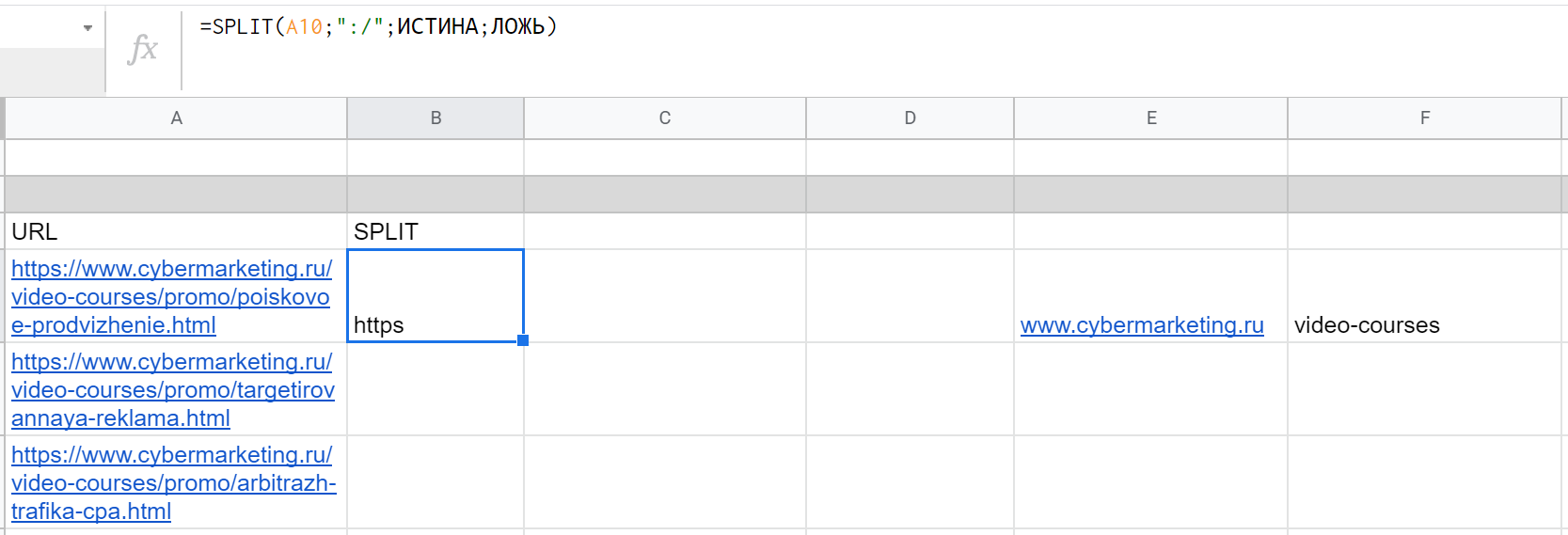
Главный недостаток — множество лишних «технических» ячеек, которые могут мешать, может понадобиться их скрывать. Извлекать отдельные фрагменты текста можно и другими способами.
REGEXMATCH, REGEXEXTRACT, REGEXREPLACE
Все эти три функции работают с регулярными выражениями — специальным языком для гибких манипуляций с текстами. REGEXMATCH ищет совпадения, REGEXEXTRACT извлекает по шаблону нужный фрагмент, а REGEXREPLACE заменяет одну часть текста на другую. Синтаксис похожий: первый аргумент — текст, а второй — само регулярное выражение; в REGEXREPLACE есть еще третий — текст, который нужно вставить.
Примеры:
- =REGEXEXTRACT("https://www.cybermarketing.ru/video-courses/promo/poiskovoe-prodvizhenie.html";"[^/]+$") — результатом будет "poiskovoe-prodvizhenie.html".
- =REGEXMATCH("mail_mail.123@gmail.com";"^([a-z0-9_-]+\.)*[a-z0-9_-]+@[a-z0-9_-]+(\.[a-z0-9_-]+)*\.[a-z]{2,6}$") — ИСТИНА, так как в строке корректный адрес электронной почты.
- =REGEXREPLACE("Google — это один из самых посещаемых сайтов в мире, второй по популярности поисковик Рунета и лидер мобильного трафика. Поэтому нет никаких сомнений, что контекстная реклама Google Adwords — эффективный канал для продвижения бизнеса. Google Адвордс позволит охватить большую аудиторию поиска Google и пользователей мобильных устройств на базе Android.";"(Adwords)|(Адвордс)|(Эдвордс)";"Ads") — здесь в тексте будет везде правильно написано название сервиса.
Вообще регулярные выражения — тема для отдельного материала. Сначала кажется, что суперсложно, но когда начинаешь разбираться, становится гораздо легче. Практиковаться можно не только в Google Docs, но и на специальных тренажерах, например, regex101.com. Но имейте в виду, что Таблицы поддерживают не все возможности, которые есть в PCRE2 (PHP) или ECMAScript (JavaScript). Вся информация о синтаксисе RE2 (Google).
Читайте также: 5 способов вычитать текст, если все глаза замылились
UNIQUE, COUNTUNIQUE
Функция UNIQUE берет только те строки, которые ни разу не повторяются, то есть позволяет почистить набор данных от дубликатов. Весьма полезная штука в SEO, PPC, веб-аналитике. Уникальные строки возвращаются в том же порядке, в котором располагаются в диапазоне/массиве.
Синтаксис: =UNIQUE(A2:A100) или =UNIQUE({"вебинар";"видеокурс";"интенсив";"вебинар";"статья";"конференция"}) — тут в столбец выйдут по порядку 5 элементов этого массива, а не 6, потому что два из них неуникальные.
Если нужно не выводить, а только подсчитать количество уников, есть функция COUNTUNIQUE. В нее можно передавать набор из произвольного числа аргументов: значений и диапазонов. Синтаксис: =COUNTUNIQUE(1; 1; 2; 3; 5; 8; 13; A2; B6:B9)
ПОИСК (SEARCH), НАЙТИ (FIND)
Обе функции делают одно и то же: возвращают порядковый номер символа, на котором запрос впервые встречается в тексте. Первым аргументом передаем, что искать, вторым — где искать, третьим — с какого символа искать (поиск идет с начала, учитываются все символы, в том числе пробелы). (В отличие от ЛЕВСИМВ и ПРАВСИМВ, нельзя передать ноль в качестве последнего аргумента.)
Разница лишь в том, что НАЙТИ (FIND) учитывает регистр, а ПОИСК (SEARCH) — нет. Примеры:
- =НАЙТИ("!";"Привет, мир!";1) — результатом будет 12.
- =НАЙТИ("привет";"Привет, мир!";1) — тут получится ошибка #ЗНАЧ, так как функция чувствительна к регистру.
- =ПОИСК("привет»;"Привет, мир!";1) — здесь функция сработает нормально, вернется 1.
- =ПОИСК(",";"Привет, мир!";4) — тут на выходе будет 7. (Важно: хотя поиск начинается с 4 символа, функция вернет позицию, где происходит совпадение, именно с начала строки — а не с того символа, с которого начинается поиск.)
- =ПОИСК("р";"Привет, мир!";1) — ответ 2, потому что учитывается только первое совпадение, которое ближе к левой части, началу строки. Если встречается дальше повторно, уже никак не влияет.
Результаты выполнения функции — позиции символов/подстрок — пригодятся, например, для дальнейшей работы с ЛЕВСИМВ, ПРАВСИМВ или ПСТР. Но сами по себе они не понадобятся, если нужно просто проверить: есть в тексте нужное слово или нет. TRUE или FALSE вместо бесполезных цифр поможет получить ЕОШИБКА (ISERROR) (или похожая функция ЕСЛИОШИБКА) в сочетании с функциями IF или IFS (иногда еще нужен NOT). К примеру:
- =IF(ISERROR(SEARCH("paid";"https://www.cybermarketing.ru/video-courses/paid/prodvinutyj-kurs-seo.html";1));"Курс бесплатный";"Курс платный") — здесь функция вернет именно "Курс платный".
- =IFS(НЕ(ЕОШИБКА(НАЙТИ("paid";"https://www.cybermarketing.ru/video-courses/promo/kontekstnaya-reklama.html")));"Курс платный";НЕ(ЕОШИБКА(НАЙТИ("promo";"https://www.cybermarketing.ru/video-courses/promo/kontekstnaya-reklama.html")));"Курс бесплатный") — а здесь получится "Курс бесплатный" (для двух вариантов, конечно, слишком сложно, но для большого количества развилок — вполне).
Читайте также: Основные показатели эффективности интернет-рекламы и маркетинга
ПОДСТАВИТЬ (SUBSTITUTE)
ПОДСТАВИТЬ (SUBSTITUTE) — текстовая функция Google Таблиц, которая сначала находит в тексте нужный фрагмент, затем заменяет его на другой (как обычно можно отправить строки как есть или ячейки с соответствующими данными). Аргументы:
- Текст, для которого нужны поиск и замена.
- Строка, которую нужно найти и удалить.
- Строка, которую нужно подставить вместо.
- Порядковый номер вхождения строки, которую нужно заменить (необязательно). (По умолчанию все совпадения будут заменяться.)
На злобу дня: =ПОДСТАВИТЬ("Привет, мир!";"мир";"карантин") — "Привет, карантин!". Еще пример: =ПОДСТАВИТЬ("Привет, мир!";"р";"г";2) —"Привет, миг!" (‘р’ встречается раньше, но специально указано, что брать следует второй символ по счету).
Важно: функция SUBSTITUTE не различает, является строка отдельным словом или частью другого. Замена будет производиться в любом случае. В более сложных кейсах лучше использовать функции REGEX — для работы с языком регулярных выражений.
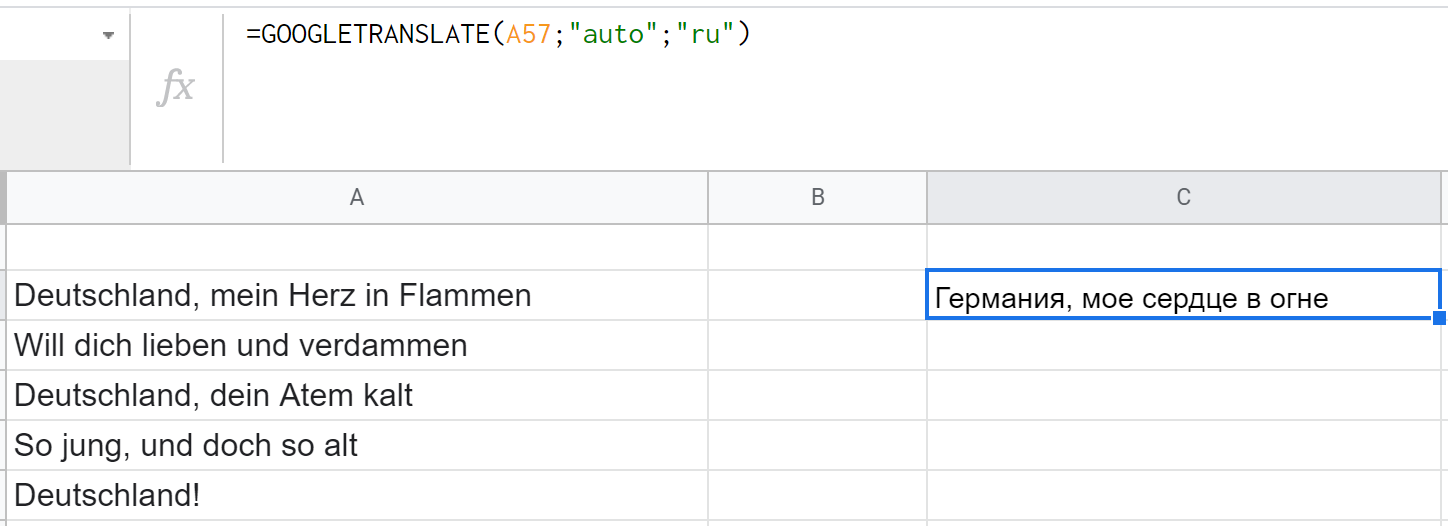
DETECTLANGUAGE и GOOGLETRANSLATE
DETECTLANGUAGE умеет определять язык текста, а GOOGLETRANSLATE — переводить текст с одного языка на другой.
DETECTLANGUAGE принимает один аргумент — текст или диапазон. (Работает только с одномерным столбцом, при передаче диапазона вида A2:B8 выдаст ошибку — обойти можно только через массив.) Если в диапазоне будут тексты на нескольких языках, функция определит язык лишь первого попавшегося фрагмента.
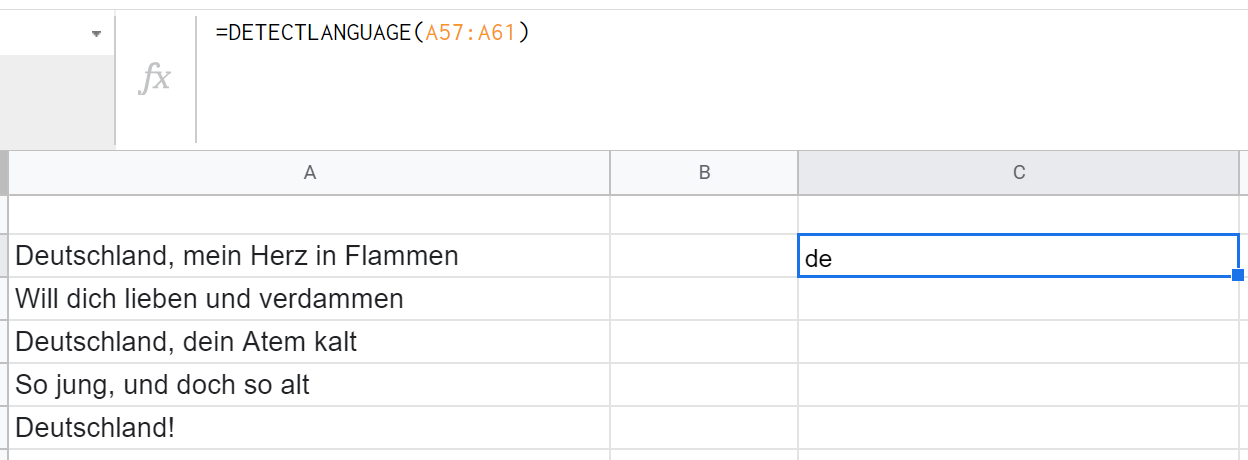
GOOGLETRANSLATE работает с тремя параметрами (два последних необязательные):
- Текст, который нужно перевести.
- Язык оригинала в таком же формате, каким оперирует DETECTLANGUAGE. (Кстати, можно указать "auto" и он будет определен автоматически — то есть вкладывать одну функцию в другую для этих целей не нужно.)
- Язык перевода — аналогично — двумя буквами. (По умолчанию функция берет язык операционной системы, но это не всегда работает, поэтому лучше указывать отдельно.)
С диапазонами не получится, только с отдельными ячейками/строками.
ТЕКСТ (TEXT) И ЗНАЧЕН (VALUE)
Функция ТЕКСТ (TEXT) преобразует числовой формат в текстовый — это может понадобится, например, для динамических таблиц с использованием QUERY, красивого представления данных в отчетах. Первый аргумент — число, дата и/или время, второй — шаблон для форматирования. (‘?’, ‘*’, а также дробные форматы не поддерживаются.) Примеры:
- =ТЕКСТ("21/12/2012";"mmm d yyyy") — здесь получится "дек. 21 2012".
- =ТЕКСТ("199,99"; "#,###") — тут результатом будет 200.
- =ТЕКСТ(100,789; "$0,00") — округление и представление в долларах — $101.
- =ТЕКСТ("10000001"; "#,##0") — "10 000 001".
(Все варианты можно посмотреть в справке, а также в разделе «Формат» → «Числа» → «Другие форматы».)
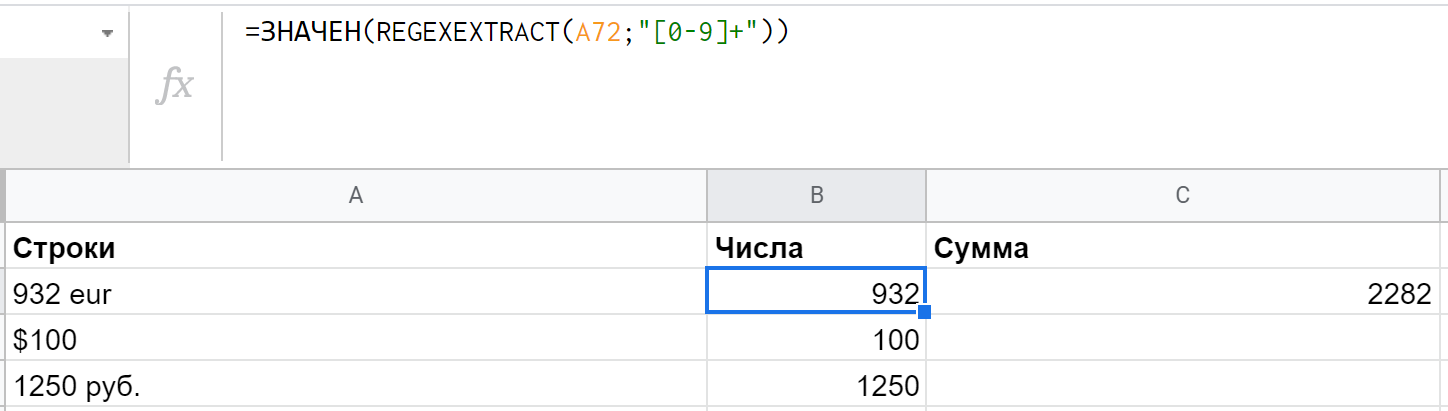
ЗНАЧЕН (VALUE) делает совершенно противоположное — преобразует текст или дату в число. На вход принимает единственный аргумент — строку. Изменение формата может понадобиться, например, когда мы извлекаем данные из текста с помощью REGEXEXTRACT, а потом их нужно использовать для функций суммирования, подсчета среднего арифметического и т. п.
Читайте также: 11 инструментов для конвертации файлов: документов, изображений, фото, видео, аудио
ЕТЕКСТ (ISTEXT)
ЕТЕКСТ (ISTEXT) проверяет, есть в ячейке текст или нет. Если там текстовое значение, возвращает ИСТИНА, если найдет число или пустую ячейку — ЛОЖЬ. Так:
- =ЕТЕКСТ("123") — TRUE, так как данные, заключенные в кавычки, передаются как строка.
- =ЕТЕКСТ(123) — FALSE, потому что числа передаются без кавычек.
- =ЕТЕКСТ("") — тоже TRUE, строка пустая, но все же это строка.
Эта функция чаще используется в условных конструкциях (IF, IFS).
СОВПАД (EXACT)
СОВПАД (EXACT) — специальная функция Таблиц для сравнения двух строк: если они полностью совпадают, вернется TRUE, если нет — FALSE. Важны и пробелы, и регистры. К примеру, =СОВПАД("Cybermarketing";"CyberMarketing") выдаст ЛОЖЬ, так как по одному символу они отличаются.
Если регистр не важен, гораздо проще использовать обычные операторы, например: =ЕСЛИ("CyberMarketing"="Cybermarketing";"Совпадают";"Не совпадают") — здесь будет "Совпадают".
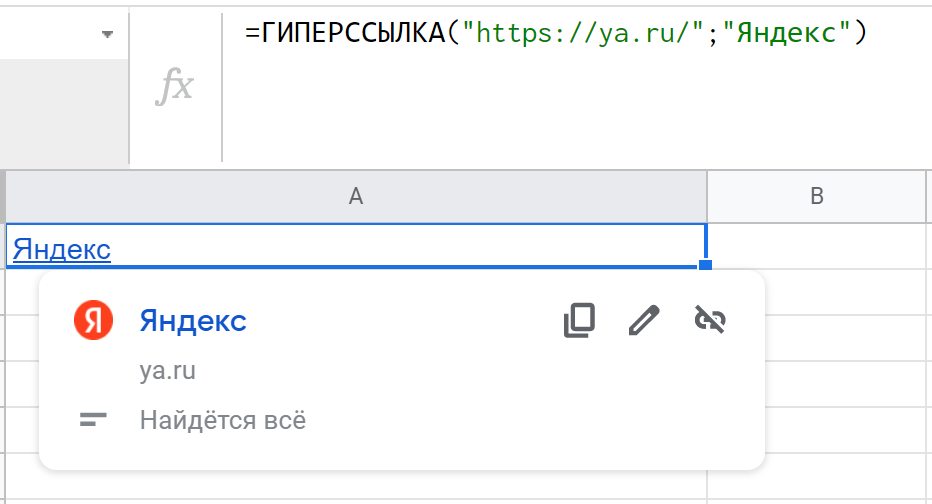
ГИПЕРССЫЛКА (HYPERLINK)
ГИПЕРССЫЛКА (HYPERLINK) создает в ячейку гиперссылку. Первый аргумент — полный URL, второй (необязательный) — текст ссылки.
Если протокол не указан, по умолчанию используется "http://". Если текстом ссылки указана пустая строка "", ячейка отображается пустой, но ссылка все равно будет работать.
На практике эта функция нужна редко, только если важно скрыть целый URL за анкором. В остальных случаях Google Таблицы автоматически делают адреса страниц/сайтов кликабельными.
А о том, как правильно работать со ссылками на сайте, вы сможете узнать с помощью статей, вебинаров, курсов по SEO от CyberMarketing.
